
The most interesting case of information sharing is the project data and information handover. It covers all the engineering information included into the project scope: specifications and datasheets, OEM MRBs, compliance certificates, construction and inspection certificates, operations and maintenance manuals, as-built documentation, spare parts and items projections and many others.
According to AVEVA survey staggering 90% of Oil & Gas projects are delayed due to handover challenges.
They, in turn, trigger delays in startup and directly impact costs and safety of future operations. By many experts, partial and inconsistent asset information increases operation costs by 8-10%.
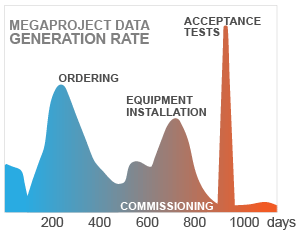
Situation in the water treatment and desalination projects is quite similar. As seen in the figure above the planned handover adds another 3-4 months to the project duration.
Penalties for delays are high. Example is the desalination project of above 150 MLD recently executed by "XXL" company: the handover added over US$ 5 million to the project planned engineering expenses, which may be estimated at 7% of the total costs or US$ 10 million. (The cause is trivial - the documentation quality and scope creep.)
The above-mentioned case is not unique at all. The experienced project planners routinely add 4% (!) to the annual engineering budget to cover the data handover.
The handover problem grows in proportions due to the engineering data volume tremendous escalation - phenomenon observed lately in desalination projects. For instance, the typical file directory of the SWRO project of above 150 MLD may contain more than 100,000 files, total of over 100 GB.
Digital transformation and the industrial IoT advances turn this escalation into Big Data tsunami, which spares neither EPC nor PPP projects.
On the bright side - to the project owner, handover is the biggest opportunity to gain genuine digital experience - the digital transformation aim. In other words, handover is where we win or lose the client.
I vividly remember some project executed in the past. Despite the project satisfying engineering, management and progress, it failed miserably on the collaboration criteria. The cause for a buildup of mistrust was a contractor total unwillingness to share the information facilitating the main scope understanding and auditing (for fear of the proprietary data leak). Ironically, most of this "know-how" information - the engineering guideline and procedures, OEM catalogs & standards - are on the internet now.
Let's image the opposite situation - we make all the project information transparent (even a data perceived by old-school engineers as know-how) and dump this Big Data in the form of documents and images upon the client. Will the client start re-selling the project copies? Or more specifically
Will Crenger users start re-selling the FEED documentation packages for 20-440 MLD SWRO desalination plants offered for free? With thousands of documents?
The answer is NO because they are too big for a human being to grasp.
It takes over 7 hours (!) to auto-generate a single package by my laptop equipped with a 4-core processor. How long does it take for a human being to reverse-engineer the logic of these documents? Eternity, especially bearing in mind that the project owner happens not to be an expert in the data storage and processing.
Converting hundreds of megabytes of data into XLS and DOC documents destroys the data most precious attribute - relationships between numbers - the attribute the highly-paid data scientists are chasing for in sieving day and night through Big Data. (Another interesting fact of the data-to-document conversion is that documentation packages are at least twice as big as the project database.)
Relationships are a new know-how, and it is NOT PRESENT in the documents handed over to the client. It is these relationships that allow aggregating the inputs of hundreds of processes across multiple disciplines, and easy data navigation. They create an illusion of ultimate data transparency.
To turn the handover from big risk to fail into an opportunity to win the client, we need to disrupt it - to move from handover as a single documentation transfer event (at the end of project execution) to the data sharing as a life service. The latter exposes neither relationships nor algorithms to the client as they are hidden deep in the software now.
This concept is not new; it is a core of the Project-Plant Life Cycle Management, and crenger.com is its practical implementation.
Crenger.com starts this service from Day 0 of the project and tracks every new bit of information progressively added to the project. To handle Big Data tsunami mentioned above, crenger.com treats differently each class of information.
- Data forming the project scope (private domain, traceable)
- Data needed to create the project scope (private domain, traceable)
- Supporting data (public domain, not traceable)
- Historical data on previous projects (public domain, not traceable)
Type 1 is mostly derived or secondary data, while Type 2 is a primary one (used to create Type 1). It means that Type 1 may not be stored physically; it may be compiled every time the client asks for it. Examples are equipment datasheets and specifications, project specification, control & operation sequences book, etc.
The boundary between Type 2 and Type 3 is volatile - more know-how pieces are keeping posted on the internet, and real company expertise is in predicting the exact direction of boundary drifting. Crenger.com does not store Type 3 accounting for over 30% of the project digital volume. Crenger.com bookmarks it with special Chrome browser extension - CRENMARK downloadable from the site.